How (Not) to Sort Items: A Lesson from Public Transit in Pittsburgh
When I took a trip to Pittsburgh last year, I needed to figure out how to get around on public transit. I went to the website of the local transit authority, and when I got to the schedules page, something seemed off.
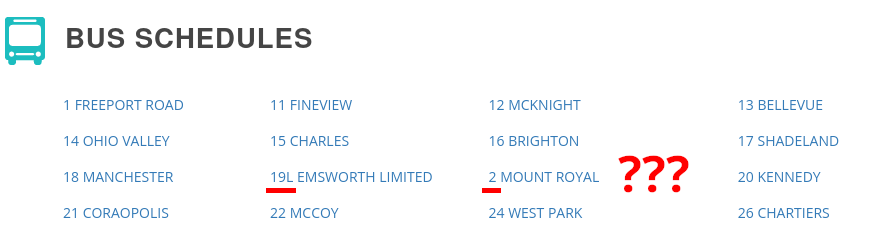
The list of bus schedules started off with 1, 11, 12, and 13. When I first saw this, I thought it was a bit odd, but I guessed that maybe they skipped some numbers for discontinued routes or some other historical reason.
But later the schedule went 18, 19L, and then… 2. At that point I knew exactly what happened: The schedules were sorted by the individual digits and not the numbers.
This is lexicographical or “alphabetical” sorting. In this sorting method, you start by comparing the first letter/character of each item, and the item with the earlier letter comes first. If the first letter is the same for both, you compare the next letters, and so on. This logic applies to digits as well: In the bus schedules, 19L comes before 2 because of the first digit. Lexicographical sorting is the usual way that text strings are sorted in software, and it makes sense for most types of text. For numbers, though, it leads to unintuitive results.
The simplest solution is to make sure the items are represented as actual numbers in the software before sorting them, which will result in numerical sorting. But that solution doesn’t work here because the route numbers aren’t all pure numbers: You may have already noticed the “L” suffix on route 19L, and there are other routes that have letter prefixes.
With a mix of letters and digits, one solution is to use “natural sorting,” and there are several different software libraries that implement it, although the details can vary. But because these route numbers follow a consistent format, a natural sorting library might be a bit much. I think it would be better to implement a custom sorting procedure, and this is what I’ve come up with:
- Split each route number into a letter prefix, a number, and a letter suffix. The prefix and suffix are optional (may be empty).
- Compare the prefixes of the route numbers. If the prefixes are different, then the route with the earlier letter comes first. (An empty prefix comes before all letters. This is handled automatically since the empty string comes before all other strings in lexicographical sorting.)
- If the prefixes are the same, compare the numbers numerically. This may require converting from a text string to a number before comparing.
- If the prefixes and numbers are the same, compare the suffixes. This is similar to the comparison for the prefixes: Earlier letters come first, and an empty suffix comes before all others. This ensures that 51 comes before 51L, and that 61A, 61B, 61C, and 61D are sorted in that order.
I’ve created a userscript that fixes the sorting on the schedule page according to what I’ve described above. If you’re not familiar with userscripts, they’re custom bits of code that can run on Web pages to modify or enhance them. Chrome has built-in support for them, and for Firefox there are extensions like Greasemonkey that will add the necessary functionality. To install the userscript, first install the extension if needed. Then visit the link to the userscript and click “Raw.” You should be prompted to install the userscript into your browser. (Note that this process does not work on mobile devices; support for userscripts on mobile seems to be rather limited.)
A final note: This sorting procedure might change in the future. PRT has proposed a simplified route naming system that would add prefixes to most bus lines to indicate the type of service. Under this new system, it might make more sense to disregard the prefix entirely and sort by the number alone. If and when this new system is implemented I will update the userscript.